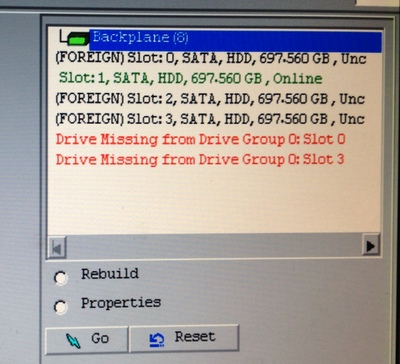
Case Study: Anatomy Of A Failed ServerIn February 2014, one of our clients' servers went dark overnight. The server was running Citrix XenServer 5.5 with Microsoft Small Business Server 2008. Both XenServer and SBS were offline, but the broadband service was active, and other machines on the network were alive and we were able to connect to them remotely. Thus we knew something had happened to the server, and it wasn't just a power failure or internet outage. It might have been a simple cable problem, it might be powered off, or something more serious. The failure occurred overnight and we discovered it on Saturday morning, so we made arrangements to gain entry to the building and see what was going on. Once at the console, we were greeted with: I9990301 Hard Disk Drive Boot Sector Error This is an IBM/Lenovo BIOS message, so the problem was that the BIOS couldn't see the volume on the storage array even to allow XenServer to start. The MegaRAID BIOS in the Lenovo told the story: the logical volume was offline, and 3 out of 4 physical drives were reporting errors: 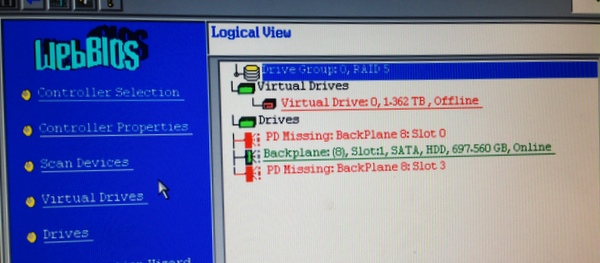
In a situation like this, there's a temptation to use the onboard utilities to see if a “repair” will bring the volume back to life. The problems with the drive might be a small number of bad sectors, or just a minor bit of easy-to-fix corruption in the RAID array configuration. But the risk is that this will complicate any repairs required by data recovery experts in the event that it doesn't do the trick. Having found that the server was dead, we altered the client's MX records to allow email to flow to a temporary location until the server could be put back online. We took some advice from a data recovery firm who specialises in RAID arrays, and decided to first investigate the possibility of bringing the server back to life with the existing drives. True, the drives could no longer be trusted, but if the server could be put back online, a more recent backup could be taken for recovery to new drives. The primary whole-server backup was some 20 hours old (as of the time of the failure), plus some secondary backups which were more recent. So it would have been preferable to make a backup that was 0 hours old. The data recovery firm advised that the drives contained bad sectors, so it wasn't necessarily going to be a simple fix. In fact they quoted a repair that would either take days or weeks (budget option), or the job could be expedited for a fee which the client judged to be uneconomic given the amount of data that would be lost by restoring the prior whole-server backup. So we proceeded with a restore, and kept the old failed drives as a fall-back in case the backup turned out to be unusable. We installed some new disk drives and partitioned them into a redundant volume, then installed the latest XenServer 6.2. We connected XenCenter on a workstation to the XenServer instance, upgraded to XenServer 6.2 Service Pack 1, created a new virtual machine and created some volumes. We mounted the SBS 2008 DVD 1 and the USB backup drive and booted. The Repair option of the Windows setup provides an option to restore the entire system. After a few minutes it found the backup, which contained C: and D: volumes, and started the restore. (This process saw the backup drive itself as C: but this didn't create a problem with the recovery.) Restoration of C: completed quickly (about an hour) but the process did not restore D:. After booting the system, it was clear why: the second volume was assigned as E: by Windows, and the DVD drive was D:, so it saw the DVD as the second volume that D: was to be restored to. So after reassigning the drive letters, we were able to restore the D: in the backup set to the logical volume D: using the backup tool in Windows. (Note that it was not necessary to change the volume letter to D: in order to restore “D:” except that the system expected this volume to be called “D:”.) This process took longer (four hours), and after a reboot everything was back online, including Microsoft Exchange, which had its stores on D:. The file data could be copied back from a secondary backup that was taken only a few hours before the outage, so little was lost. The email store, however, lost all received emails from the last backup to the outage, some 20 hours. However, we found that when Outlook was opened, the offline mailbox file (.OST) which contained messages received on the day of the failure, those messages were copied back to the server. So the only messages lost were those that arrived in the Information Store but which were not copied down to a user's local Outlook. After this we configured the SBS POP3 Connector to download the email that had queued into upstream POP3 accounts, then switched the MX records back. Some manual interventions required on the server were:
Copyright © 1996-2023 Cadzow TECH Pty. Ltd. All rights reserved. Information and prices contained in this website may change without notice. Terms of use. Question/comment about this page? Please email webguru@cadzow.com.au |